Project: Vision Transformer Analysis
![]()
![]()
![]()
![]()
![]()
![]()
![]()
This is the final project for the course AIST4010. More details on the project can be found in the report. This project is done in April 2024.
Report: ![]()
Overview
Project Goals
The project investigates the generalizability of Vision Transformers (ViTs) compared to Convolutional Neural Networks (CNNs) for small-scale computer vision tasks. While ViTs excel in large datasets, they struggle with smaller ones. This work evaluates and compares the performance of models like ResNet, ViT, DeiT, and T2T-ViT on classification tasks using small subsets of CIFAR-10 and STL-10 datasets.
Key Contributions
- Scalability Analysis: Demonstrated performance degradation of ViTs with reduced dataset sizes, showing CNNs are more effective for small datasets.
- Computational Efficiency: Analyzed training iterations and time-to-convergence, highlighting that ViTs, while converging faster, still lack efficiency due to lower accuracy on small datasets.
- Comparison of Architectures: Implemented and trained models with similar parameter counts for fair performance evaluations.
Note: The above overview is generated by ChatGPT from the project report, which itself is not written by ChatGPT. For more details, please refer to the report.
Sections below are not generated by ChatGPT.
Models Used
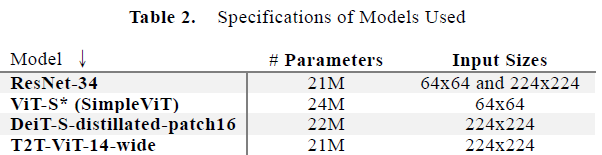
The models used have approximately the same number of parameters. The sources of the models have been provided in both the report and the header of this readme.
Experimental Results
Scalability Performance
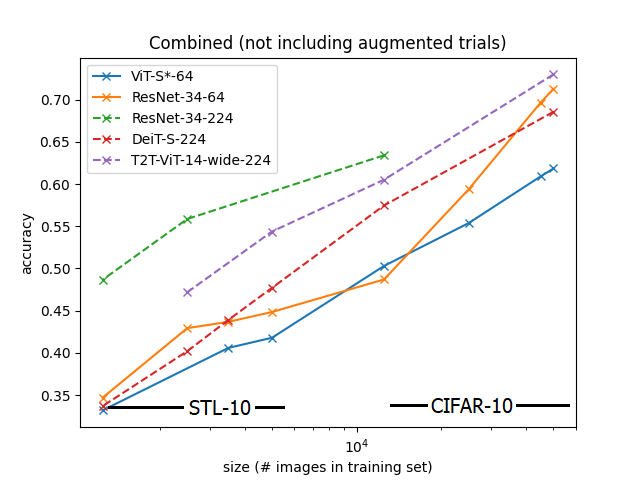
Findings: Transformer-based models perform poorly on small datasets.
- For models with the same input size, transformer-based models achieve significantly lower accuracy.
- The accuracy gap widens significantly for input shape 224x224 (the dotted lines) under a decrease of the training set size, where DeiT (red) and T2T-ViT (purple) underperforms the ResNet (green).
Computational Efficiency
| Against #iterations | Against time in second-P100 |
|---|---|
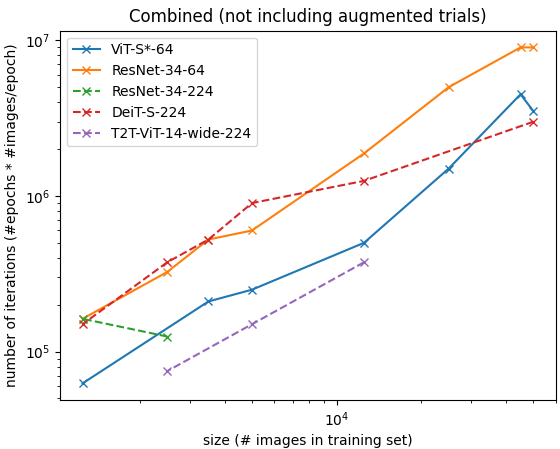 | 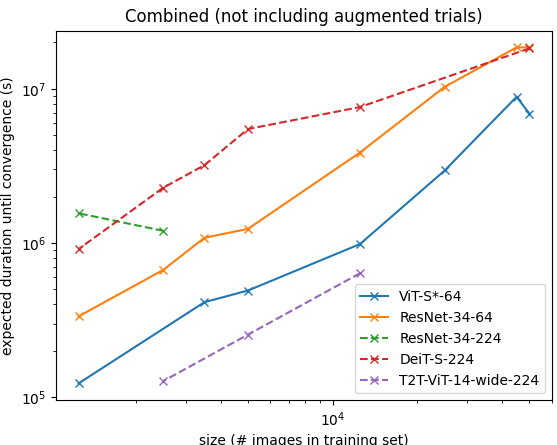 |
Findings: Transformer-based models seemed to remain computationally less efficient compared to convolution-based models over significantly small datasets.
- Note that it is an unfair comparison if we compare all models directly since they don't have the same accuracy.
- We can see that DeiT-S with input size 224x224 (red), which have a performance (accuracy) comparable to ResNet-34 with input size 64x64 (orange) while taking significantly more time to converge.
Image Segmentation Task
This segment explores UNet-based architectures for image segmentation tasks. Related code is in the models_archive/ folder. Not part of the final report.
| mAP | IoU |
|---|---|
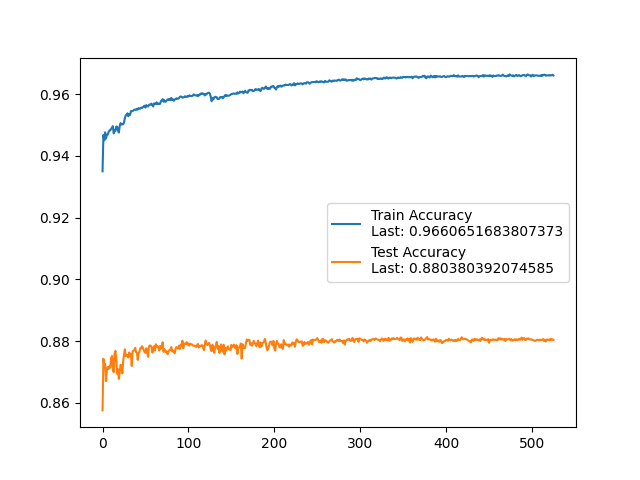 | 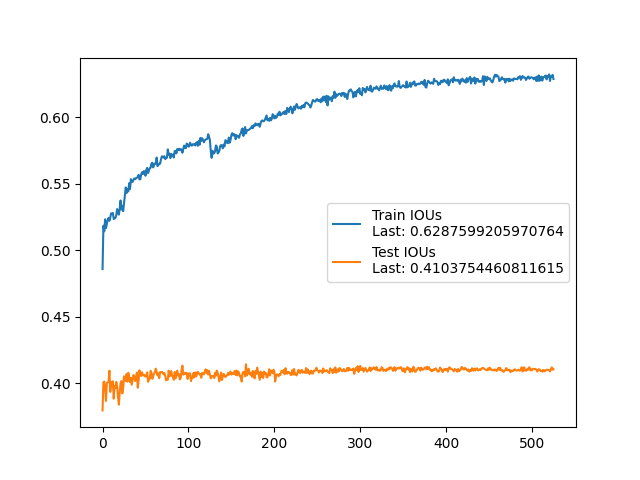 |
Resultant output:
